Welcome to Software Development on Codidact!
Will you help us build our independent community of developers helping developers? We're small and trying to grow. We welcome questions about all aspects of software development, from design to code to QA and more. Got questions? Got answers? Got code you'd like someone to review? Please join us.
How to separate DB query logic from the application other than implementing a repository on top of an ORM?
I've been doing a lot of reading on implementing the repository pattern in C# projects and found controversy, or shall I say some strong criticism, made by seemingly very smart people with previous experience with the pattern, saying that one is better off not implementing a repository on top of an ORM like Entity Framework Core.
The argument made is that EF Core is already a repository implementation, with the Context being the unit of work and each DbSet being a repository. (I don't normally do unit testing so whatever point made about that is irrelevant to me.)
p.s. I'm not sure whether the criticism applies only to generic repositories or not.
The thing is, I'm failing to see a sound alternative to separate data access code from my Application layer (business logic implementation). The suggestions I found include consuming the ORM directly from the Application layer, or doing CQRS, or even moving to a microservices architecture. The latter two I'm not interested in; the first doesn't give me the flexibility of implementing my business logic without polluting it with query logic, particularly considering that more than one database will most likely be required in this application.
Here's how I want my architecture to look like:
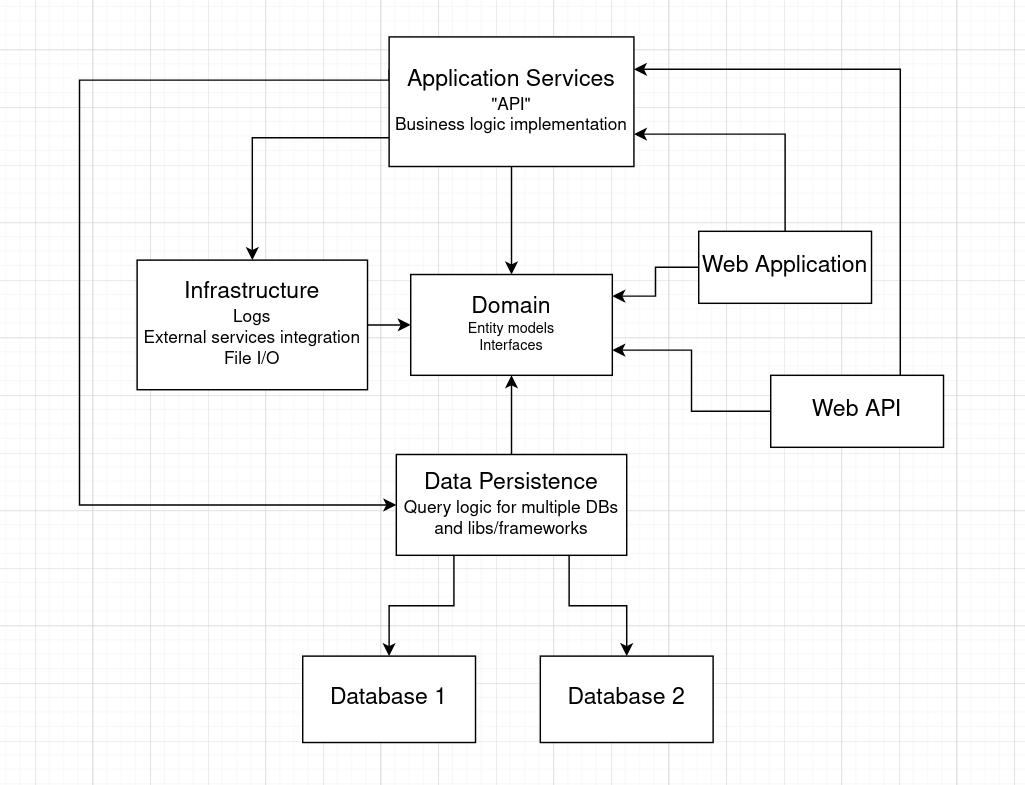
(n.b. I haven't decided about using ViewModels/DTOs for the WebApp and WebAPI instead of referencing Domain models, yet.)
For those familiar with the criticism/argument I mention, I'd like to ask how else can one achieve proper separation of concerns in my proposed architecture? Or, in other words, is there a better alternative to implementing the Data Persistence layer other than via the repository pattern?
Fun fact: This is the architecture I was planning (and started implementing) for the Codidact Core software about a year ago, before my hiatus.
Thank you!
1 answer
p.s. I'm not sure whether the criticism applies only to generic repositories or not.
This applies to generic repositories as most of their operations (e.g. get entity by id, update the entity, delete entity) are already being done by the DbSet).
consuming the ORM directly from the Application layer (..) the first doesn't give me the flexibility of implementing my business logic without polluting it with query logic, particularly considering that more than one database will most likely be required in this application.
My approach is hybrid in this case. If your application is mainly using a relational database for the operational parts (CRUD) and some others for querying external information, notifying other APIs etc. I would take the following approach:
-
consuming the ORM directly from the Application layer for the use cases that involve the primary relational database. That is, your application layer might inject the
ICustomDbContextwhich exposes the minimum required to get/update the data:DbSet Set() where TEntity : class; IQueryable ReadSet() where TEnt : class; Task SaveChangesAsync(CancellationToken cancellationToken);
This indeed couples the application to the ORM and you have some queries in the application. However, queries are actually part of the business logic and abstractions tend to complicate things (i.e. poor performance in some cases).
It is very unlikely that you will need to change the ORM in the future, but it still works if you change the relational database.
An exception for this rule is the cases when you need to write a direct query due to performance reasons. This should be placed in another class (repository) because changing the provider might need revisiting the query.
-
interacting with other databases - if your application needs to talk to other databases, the logic for this can be included in a repository class for each case. This is required because other databases come with their own specifics and you do not want to mix those specifics with the application business logic
-
consuming APIs or other services - this can be put in a separate service class. In a clean architecture, these services are implemented in the Infrastructure layer and injected (dependency inversion) in the application layer.
Note: for extensive information about why generic repositories are not fashionable anymore and how to replace them with "generic services", check out this article.

1 comment thread