Welcome to Software Development on Codidact!
Will you help us build our independent community of developers helping developers? We're small and trying to grow. We welcome questions about all aspects of software development, from design to code to QA and more. Got questions? Got answers? Got code you'd like someone to review? Please join us.
Comments on How to separate DB query logic from the application other than implementing a repository on top of an ORM?
Post
How to separate DB query logic from the application other than implementing a repository on top of an ORM?
I've been doing a lot of reading on implementing the repository pattern in C# projects and found controversy, or shall I say some strong criticism, made by seemingly very smart people with previous experience with the pattern, saying that one is better off not implementing a repository on top of an ORM like Entity Framework Core.
The argument made is that EF Core is already a repository implementation, with the Context being the unit of work and each DbSet being a repository. (I don't normally do unit testing so whatever point made about that is irrelevant to me.)
p.s. I'm not sure whether the criticism applies only to generic repositories or not.
The thing is, I'm failing to see a sound alternative to separate data access code from my Application layer (business logic implementation). The suggestions I found include consuming the ORM directly from the Application layer, or doing CQRS, or even moving to a microservices architecture. The latter two I'm not interested in; the first doesn't give me the flexibility of implementing my business logic without polluting it with query logic, particularly considering that more than one database will most likely be required in this application.
Here's how I want my architecture to look like:
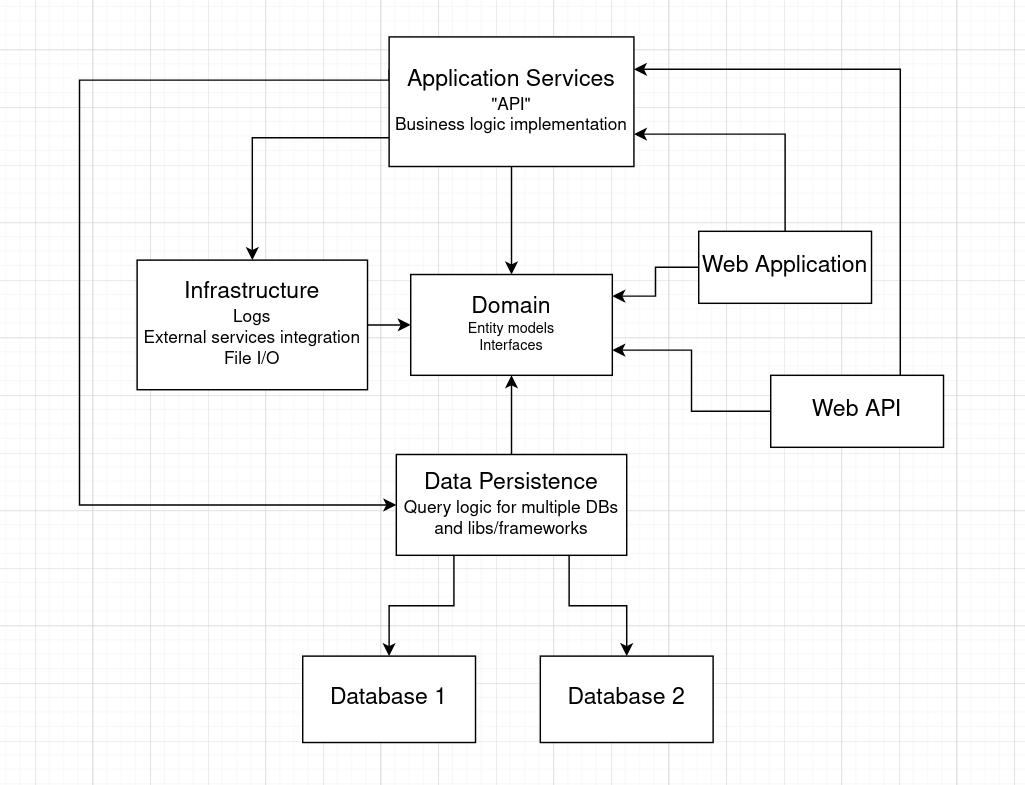
(n.b. I haven't decided about using ViewModels/DTOs for the WebApp and WebAPI instead of referencing Domain models, yet.)
For those familiar with the criticism/argument I mention, I'd like to ask how else can one achieve proper separation of concerns in my proposed architecture? Or, in other words, is there a better alternative to implementing the Data Persistence layer other than via the repository pattern?
Fun fact: This is the architecture I was planning (and started implementing) for the Codidact Core software about a year ago, before my hiatus.
Thank you!

1 comment thread