Welcome to Software Development on Codidact!
Will you help us build our independent community of developers helping developers? We're small and trying to grow. We welcome questions about all aspects of software development, from design to code to QA and more. Got questions? Got answers? Got code you'd like someone to review? Please join us.
Post History
First, let's see how Zalgo Text works. Unicode Combining Characters Unicode defines the concept of combining characters. Basically, some characters can be combined with others, to "make/create"...
#4: Post edited
by
 hkotsubo
·
2023-12-04T12:54:12Z (over 1 year ago)
hkotsubo
·
2023-12-04T12:54:12Z (over 1 year ago)
- First, let's see how Zalgo Text works.
- ---
- # Unicode Combining Characters
- [Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
- > Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).
- Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
- Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
- | Character | Code Point * | Category | Name |
- |-----------|--------------|-----------|--------------------------------|
- | T | U+0054 | Lu | LATIN CAPITAL LETTER T |
- | ̃ | U+0303 | Mn | COMBINING TILDE |
- | ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
- | ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
- | ̧ | U+0327 | Mn | COMBINING CEDILLA |
- | ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
- | ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
- | ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
- <sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
- So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
- T̃͟͏̧̟͓̯̘͓͙͔
- <br>
- An enlarged image of the above:
[![letter T with 11 combining characters][1]][1]- The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
- ---
- Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
- Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
- T <-- letter "T" without combining characters
- T̃ <-- adding COMBINING TILDE
- T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
- T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
- T̃͟͏̧ <-- adding COMBINING CEDILLA
- T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
- T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
- T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
- T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
- <br>
- T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
- <br><br>
- T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
- <br><br><br>
- T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
- <br><br><br>
- As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
- And now that we know how it's made, we can think of ways to detect it.
- ---
- # So how do I detect it?
- One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
- Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
- ```php
- // PHP supports Regex Unicode Properties
- $text = // string you want to check
- if (preg_match('/\p{M}{3,}/u', $text)) {
- echo "zalgo";
- } else {
- echo "not zalgo";
- }
- ```
- I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
- And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
- In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
- ཧྐྵྨླྺྼྻྂ
- <br>
- An enlarged image, so we can see it in all its glory:
[![caractere tibetano HAKṢHMALAWARAYAṀ][2]][2]- Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
- One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
- ---
- Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
- ```python
- # Python
- from unicodedata import combining
- text = # string I want to check
- count = 0
- max_allowed = 3 # maximum of 3 consecutive combining characters allowed
- for c in text:
- if combining(c):
- count += 1
- if count > max_allowed:
- print('Zalgo!')
- break
- else:
- count = 0
- else:
- print('not zalgo')
- ```
- I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
- Many programming languages - if not all, at least the "mainstream" ones - have some way to work with Unicode data, so the code above is pretty straightforward to adapt.
- ---
- Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
- > this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
- <br>
- Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
- ---
- Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
- Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
- Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
- ```php
- // PHP, checking valid combining characters in Portuguese
- if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
- echo "invalid\n";
- } else {
- echo "valid\n";
- }
- // PS: it's a "simplified" version, because some vowels don't accept all the accents
- ```
- This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
- And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
- Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
- [1]: https://i.stack.imgur.com/olrFQ.png
- [2]: https://i.stack.imgur.com/3e77q.png
- [3]: https://www.fileformat.info/info/unicode/char/327/index.htm
- First, let's see how Zalgo Text works.
- ---
- # Unicode Combining Characters
- [Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
- > Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).
- Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
- Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
- | Character | Code Point * | Category | Name |
- |-----------|--------------|-----------|--------------------------------|
- | T | U+0054 | Lu | LATIN CAPITAL LETTER T |
- | ̃ | U+0303 | Mn | COMBINING TILDE |
- | ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
- | ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
- | ̧ | U+0327 | Mn | COMBINING CEDILLA |
- | ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
- | ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
- | ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
- <sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
- So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
- T̃͟͏̧̟͓̯̘͓͙͔
- <br>
- An enlarged image of the above:
- 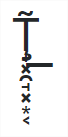
- The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
- ---
- Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
- Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
- T <-- letter "T" without combining characters
- T̃ <-- adding COMBINING TILDE
- T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
- T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
- T̃͟͏̧ <-- adding COMBINING CEDILLA
- T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
- T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
- T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
- T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
- <br>
- T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
- <br><br>
- T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
- <br><br><br>
- T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
- <br><br><br>
- As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
- And now that we know how it's made, we can think of ways to detect it.
- ---
- # So how do I detect it?
- One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
- Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
- ```php
- // PHP supports Regex Unicode Properties
- $text = // string you want to check
- if (preg_match('/\p{M}{3,}/u', $text)) {
- echo "zalgo";
- } else {
- echo "not zalgo";
- }
- ```
- I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
- And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
- In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
- ཧྐྵྨླྺྼྻྂ
- <br>
- An enlarged image, so we can see it in all its glory:
- 
- Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
- One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
- ---
- Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
- ```python
- # Python
- from unicodedata import combining
- text = # string I want to check
- count = 0
- max_allowed = 3 # maximum of 3 consecutive combining characters allowed
- for c in text:
- if combining(c):
- count += 1
- if count > max_allowed:
- print('Zalgo!')
- break
- else:
- count = 0
- else:
- print('not zalgo')
- ```
- I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
- Many programming languages - if not all, at least the "mainstream" ones - have some way to work with Unicode data, so the code above is pretty straightforward to adapt.
- ---
- Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
- > this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
- <br>
- Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
- ---
- Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
- Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
- Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
- ```php
- // PHP, checking valid combining characters in Portuguese
- if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
- echo "invalid\n";
- } else {
- echo "valid\n";
- }
- // PS: it's a "simplified" version, because some vowels don't accept all the accents
- ```
- This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
- And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
- Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
- [1]: https://i.stack.imgur.com/olrFQ.png
- [2]: https://i.stack.imgur.com/3e77q.png
- [3]: https://www.fileformat.info/info/unicode/char/327/index.htm
#3: Post edited
by
hkotsubo
·
2021-04-30T13:45:52Z (about 4 years ago)
- First, let's see how Zalgo Text works.
- ---
- # Unicode Combining Characters
- [Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
- > Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).
- Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
- Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
- | Character | Code Point * | Category | Name |
- |-----------|--------------|-----------|--------------------------------|
- | T | U+0054 | Lu | LATIN CAPITAL LETTER T |
- | ̃ | U+0303 | Mn | COMBINING TILDE |
- | ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
- | ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
- | ̧ | U+0327 | Mn | COMBINING CEDILLA |
- | ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
- | ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
- | ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
- <sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
- So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
- T̃͟͏̧̟͓̯̘͓͙͔
- <br>
- An enlarged image of the above:
- [![letter T with 11 combining characters][1]][1]
- The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
- ---
- Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
- Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
- T <-- letter "T" without combining characters
- T̃ <-- adding COMBINING TILDE
- T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
- T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
- T̃͟͏̧ <-- adding COMBINING CEDILLA
- T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
- T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
- T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
- T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
- <br>
- T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
- <br><br>
- T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
- <br><br><br>
- T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
- <br><br><br>
- As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
- And now that we know how it's made, we can think of ways to detect it.
- ---
- # So how do I detect it?
- One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
- Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
- ```php
// PHP regex support Unicode Properties- $text = // string you want to check
- if (preg_match('/\p{M}{3,}/u', $text)) {
- echo "zalgo";
- } else {
- echo "not zalgo";
- }
- ```
- I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
- And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
- In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
- ཧྐྵྨླྺྼྻྂ
- <br>
- An enlarged image, so we can see it in all its glory:
- [![caractere tibetano HAKṢHMALAWARAYAṀ][2]][2]
- Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
- One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
- ---
- Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
- ```python
- # Python
- from unicodedata import combining
- text = # string I want to check
- count = 0
- max_allowed = 3 # maximum of 3 consecutive combining characters allowed
- for c in text:
- if combining(c):
- count += 1
- if count > max_allowed:
- print('Zalgo!')
- break
- else:
- count = 0
- else:
- print('not zalgo')
- ```
- I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
- ---
- Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
- > this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
- <br>
- Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
- ---
- Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
- Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
- Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
- ```php
- // PHP, checking valid combining characters in Portuguese
- if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
- echo "invalid\n";
- } else {
- echo "valid\n";
- }
- // PS: it's a "simplified" version, because some vowels don't accept all the accents
- ```
- This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
- And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
- Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
- [1]: https://i.stack.imgur.com/olrFQ.png
- [2]: https://i.stack.imgur.com/3e77q.png
- [3]: https://www.fileformat.info/info/unicode/char/327/index.htm
- First, let's see how Zalgo Text works.
- ---
- # Unicode Combining Characters
- [Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
- > Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).
- Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
- Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
- | Character | Code Point * | Category | Name |
- |-----------|--------------|-----------|--------------------------------|
- | T | U+0054 | Lu | LATIN CAPITAL LETTER T |
- | ̃ | U+0303 | Mn | COMBINING TILDE |
- | ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
- | ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
- | ̧ | U+0327 | Mn | COMBINING CEDILLA |
- | ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
- | ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
- | ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
- <sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
- So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
- T̃͟͏̧̟͓̯̘͓͙͔
- <br>
- An enlarged image of the above:
- [![letter T with 11 combining characters][1]][1]
- The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
- ---
- Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
- Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
- T <-- letter "T" without combining characters
- T̃ <-- adding COMBINING TILDE
- T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
- T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
- T̃͟͏̧ <-- adding COMBINING CEDILLA
- T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
- T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
- T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
- T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
- <br>
- T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
- <br><br>
- T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
- <br><br><br>
- T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
- <br><br><br>
- As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
- And now that we know how it's made, we can think of ways to detect it.
- ---
- # So how do I detect it?
- One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
- Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
- ```php
- // PHP supports Regex Unicode Properties
- $text = // string you want to check
- if (preg_match('/\p{M}{3,}/u', $text)) {
- echo "zalgo";
- } else {
- echo "not zalgo";
- }
- ```
- I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
- And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
- In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
- ཧྐྵྨླྺྼྻྂ
- <br>
- An enlarged image, so we can see it in all its glory:
- [![caractere tibetano HAKṢHMALAWARAYAṀ][2]][2]
- Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
- One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
- ---
- Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
- ```python
- # Python
- from unicodedata import combining
- text = # string I want to check
- count = 0
- max_allowed = 3 # maximum of 3 consecutive combining characters allowed
- for c in text:
- if combining(c):
- count += 1
- if count > max_allowed:
- print('Zalgo!')
- break
- else:
- count = 0
- else:
- print('not zalgo')
- ```
- I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
- Many programming languages - if not all, at least the "mainstream" ones - have some way to work with Unicode data, so the code above is pretty straightforward to adapt.
- ---
- Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
- > this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
- <br>
- Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
- ---
- Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
- Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
- Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
- ```php
- // PHP, checking valid combining characters in Portuguese
- if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
- echo "invalid\n";
- } else {
- echo "valid\n";
- }
- // PS: it's a "simplified" version, because some vowels don't accept all the accents
- ```
- This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
- And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
- Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
- [1]: https://i.stack.imgur.com/olrFQ.png
- [2]: https://i.stack.imgur.com/3e77q.png
- [3]: https://www.fileformat.info/info/unicode/char/327/index.htm
#2: Post edited
by
hkotsubo
·
2021-04-29T16:53:11Z (about 4 years ago)
- First, let's see how Zalgo Text works.
- ---
- # Unicode Combining Characters
- [Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
> Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm)) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).- Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
- Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
- | Character | Code Point * | Category | Name |
- |-----------|--------------|-----------|--------------------------------|
- | T | U+0054 | Lu | LATIN CAPITAL LETTER T |
- | ̃ | U+0303 | Mn | COMBINING TILDE |
- | ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
- | ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
- | ̧ | U+0327 | Mn | COMBINING CEDILLA |
- | ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
- | ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
- | ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
- <sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
- So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
- T̃͟͏̧̟͓̯̘͓͙͔
- <br>
- An enlarged image of the above:
- [![letter T with 11 combining characters][1]][1]
- The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
- ---
- Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
- Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
- T <-- letter "T" without combining characters
- T̃ <-- adding COMBINING TILDE
- T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
- T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
- T̃͟͏̧ <-- adding COMBINING CEDILLA
- T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
- T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
- T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
- T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
- <br>
- T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
- <br><br>
- T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
- <br><br><br>
- T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
- <br><br><br>
- As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
- And now that we know how it's made, we can think of ways to detect it.
- ---
- # So how do I detect it?
- One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
- Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
- ```php
- // PHP regex support Unicode Properties
- $text = // string you want to check
- if (preg_match('/\p{M}{3,}/u', $text)) {
- echo "zalgo";
- } else {
- echo "not zalgo";
- }
- ```
- I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
- And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
- In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
- ཧྐྵྨླྺྼྻྂ
- <br>
- An enlarged image, so we can see it in all its glory:
- [![caractere tibetano HAKṢHMALAWARAYAṀ][2]][2]
- Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
- One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
- ---
- Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
- ```python
- # Python
- from unicodedata import combining
- text = # string I want to check
- count = 0
- max_allowed = 3 # maximum of 3 consecutive combining characters allowed
- for c in text:
- if combining(c):
- count += 1
- if count > max_allowed:
- print('Zalgo!')
- break
- else:
- count = 0
- else:
- print('not zalgo')
- ```
- I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
- ---
- Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
- > this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
- Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
- ---
- Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
- Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
- Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
- ```php
- // PHP, checking valid combining characters in Portuguese
- if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
- echo "invalid\n";
- } else {
- echo "valid\n";
- }
- // PS: it's a "simplified" version, because some vowels don't accept all the accents
- ```
- This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
- And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
- Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
- [1]: https://i.stack.imgur.com/olrFQ.png
- [2]: https://i.stack.imgur.com/3e77q.png
- [3]: https://www.fileformat.info/info/unicode/char/327/index.htm
- First, let's see how Zalgo Text works.
- ---
- # Unicode Combining Characters
- [Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
- > Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).
- Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
- Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
- | Character | Code Point * | Category | Name |
- |-----------|--------------|-----------|--------------------------------|
- | T | U+0054 | Lu | LATIN CAPITAL LETTER T |
- | ̃ | U+0303 | Mn | COMBINING TILDE |
- | ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
- | ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
- | ̧ | U+0327 | Mn | COMBINING CEDILLA |
- | ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
- | ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
- | ͓ | U+0353 | Mn | COMBINING X BELOW |
- | ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
- | ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
- <sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
- So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
- T̃͟͏̧̟͓̯̘͓͙͔
- <br>
- An enlarged image of the above:
- [![letter T with 11 combining characters][1]][1]
- The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
- ---
- Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
- Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
- T <-- letter "T" without combining characters
- T̃ <-- adding COMBINING TILDE
- T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
- T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
- T̃͟͏̧ <-- adding COMBINING CEDILLA
- T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
- T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
- T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
- T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
- <br>
- T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
- <br><br>
- T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
- <br><br><br>
- T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
- <br><br><br>
- As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
- And now that we know how it's made, we can think of ways to detect it.
- ---
- # So how do I detect it?
- One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
- Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
- ```php
- // PHP regex support Unicode Properties
- $text = // string you want to check
- if (preg_match('/\p{M}{3,}/u', $text)) {
- echo "zalgo";
- } else {
- echo "not zalgo";
- }
- ```
- I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
- And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
- In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
- ཧྐྵྨླྺྼྻྂ
- <br>
- An enlarged image, so we can see it in all its glory:
- [![caractere tibetano HAKṢHMALAWARAYAṀ][2]][2]
- Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
- One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
- ---
- Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
- ```python
- # Python
- from unicodedata import combining
- text = # string I want to check
- count = 0
- max_allowed = 3 # maximum of 3 consecutive combining characters allowed
- for c in text:
- if combining(c):
- count += 1
- if count > max_allowed:
- print('Zalgo!')
- break
- else:
- count = 0
- else:
- print('not zalgo')
- ```
- I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
- ---
- Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
- > this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
- <br>
- Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
- ---
- Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
- Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
- Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
- ```php
- // PHP, checking valid combining characters in Portuguese
- if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
- echo "invalid\n";
- } else {
- echo "valid\n";
- }
- // PS: it's a "simplified" version, because some vowels don't accept all the accents
- ```
- This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
- And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
- Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
- [1]: https://i.stack.imgur.com/olrFQ.png
- [2]: https://i.stack.imgur.com/3e77q.png
- [3]: https://www.fileformat.info/info/unicode/char/327/index.htm
#1: Initial revision
by
hkotsubo
·
2021-04-29T16:48:39Z (about 4 years ago)
First, let's see how Zalgo Text works.
---
# Unicode Combining Characters
[Unicode](http://unicode.org/main.html) defines the concept of [combining characters](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82). Basically, some characters can be combined with others, to "make/create" different ones (you can also say that they can modify other characters).
> Example: in Portuguese there's the letter `a`. But if you combine it with the [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm)) character, the result is `á`, which is a different letter (or the same letter, but with a different semantics - *sorry for the lack of accuracy, I'm not a grammar specialist*). Anyway, that makes difference in words such as "_sábia_" (wise), "_sabia_" (the verb "to know" in past tense) and "_sabiá_" (a [bird](https://www.google.com/search?q=sabi%C3%A1)).
Unicode defines more than 2000 combining characters, all contained in one of the following categories: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm).
Zalgo Text is created by applying lots of combining characters on the same letter. In many languages, it's perfectly valid to have more than one combining character on the same letter, and that's why it's allowed by Unicode. The text in the question starts with these:
| Character | Code Point * | Category | Name |
|-----------|--------------|-----------|--------------------------------|
| T | U+0054 | Lu | LATIN CAPITAL LETTER T |
| ̃ | U+0303 | Mn | COMBINING TILDE |
| ͟ | U+035F | Mn | COMBINING DOUBLE MACRON BELOW |
| ͏ | U+034F | Mn | COMBINING GRAPHEME JOINER |
| ̧ | U+0327 | Mn | COMBINING CEDILLA |
| ̟ | U+031F | Mn | COMBINING PLUS SIGN BELOW |
| ͓ | U+0353 | Mn | COMBINING X BELOW |
| ̯ | U+032F | Mn | COMBINING INVERTED BREVE BELOW |
| ̘ | U+0318 | Mn | COMBINING LEFT TACK BELOW |
| ͓ | U+0353 | Mn | COMBINING X BELOW |
| ͙ | U+0359 | Mn | COMBINING ASTERISK BELOW |
| ͔ | U+0354 | Mn | COMBINING LEFT ARROWHEAD BELOW |
<sup>\* *Unicode defines that each character has an unique numeric value, called [code point](https://en.wikipedia.org/wiki/Code_point).*</sup>
So, the text in the question starts with a letter "T" followed by 11 combining characters. This sequence produces the following:
T̃͟͏̧̟͓̯̘͓͙͔
<br>
An enlarged image of the above:
[![letter T with 11 combining characters][1]][1]
The rest of the Zalgo Text follows the same pattern: a letter with lots of combining characters. The full text consists of this pattern repeated lots of times.
---
Another thing that makes Zalgo Texts have this peculiar appearance is the stacking algorithm (described [here](https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf#page=82)), that defines what happens when more than one combining character is applied to the same letter.
Each combining character can be rendered above or below the pre-existing ones - each one has its own rules about the position it should be, but the exact rendering also depends on the font being used). Let's see below what happens when we add combining characters to the letter "T" (in each line, a new combining character is added):
T <-- letter "T" without combining characters
T̃ <-- adding COMBINING TILDE
T̃͟ <-- adding COMBINING DOUBLE MACRON BELOW
T̃͟͏ <-- adding COMBINING GRAPHEME JOINER
T̃͟͏̧ <-- adding COMBINING CEDILLA
T̃͟͏̧̟ <-- adding COMBINING PLUS SIGN BELOW
T̃͟͏̧̟͓ <-- adding COMBINING X BELOW
T̃͟͏̧̟͓̯ <-- adding COMBINING INVERTED BREVE BELOW
T̃͟͏̧̟͓̯̘ <-- adding COMBINING LEFT TACK BELOW
<br>
T̃͟͏̧̟͓̯̘͓ <-- adding COMBINING X BELOW
<br><br>
T̃͟͏̧̟͓̯̘͓͙ <-- adding COMBINING ASTERISK BELOW
<br><br><br>
T̃͟͏̧̟͓̯̘͓͙͔ <-- adding COMBINING LEFT ARROWHEAD BELOW
<br><br><br>
As we can see, Unicode allows lots of combining characters applied to the same letter, and those are "stacked" on top of (or at any other relative position, depending on the character) the previous ones, resulting in this peculiar appearance of Zalgo Texts.
And now that we know how it's made, we can think of ways to detect it.
---
# So how do I detect it?
One way to detect Zalgo Text **could be** to verify if there are "lots" of consecutive combining characters.
Different programming languages will have their own functions/libraries to work with Unicode data. In languages that support Regex Unicode Properties, you could use something like:
```php
// PHP regex support Unicode Properties
$text = // string you want to check
if (preg_match('/\p{M}{3,}/u', $text)) {
echo "zalgo";
} else {
echo "not zalgo";
}
```
I've made an example in PHP because it supports [Regex Unicode Properties](https://www.php.net/manual/en/regexp.reference.unicode.php): `\p{M}` matches any character in the "Mark" categories (the three already mentioned above: [Mn (Mark, Nonspacing)](https://www.fileformat.info/info/unicode/category/Mn/index.htm), [Me (Mark, Enclosing)](https://www.fileformat.info/info/unicode/category/Me/index.htm) and [Mc (Mark, Spacing)](https://www.fileformat.info/info/unicode/category/Mc/index.htm)).
And the [quantifier](https://www.regular-expressions.info/repeat.html) `{3,}` searches for 3 or more ocurrences: so, if there are 3 or more consecutive combining characters, the text is considered to be Zalgo. **This might or might not be enough, depending on the languages you want your application to accept**.
In some languages, the lower bound could be higher - or lower - than 3. Unicode defines the concept of [Stream-safe Text Format](https://unicode.org/reports/tr15/#Stream_Safe_Text_Format), that _kinda_ defines a limit of 30 consecutive combining characters. But in real-life applications, I guess 30 is too much, because the longest known sequence is the [tibetan character HAKṢHMALAWARAYAṀ](http://archives.miloush.net/michkap/archive/2010/04/28/10002896.html): a letter followed by 8 combining characters. It's this one (and I admit that, for those who don't know it, this can easily be mistaken as Zalgo):
ཧྐྵྨླྺྼྻྂ
<br>
An enlarged image, so we can see it in all its glory:
[![caractere tibetano HAKṢHMALAWARAYAṀ][2]][2]
Therefore, unless your application needs to accept tibetan texts, using `\p{M}{8,}` would be a valid solution. Depending on how many you use, you might end up excluding valid words in another languages (in many of them, having 2, 3 or even more combining characters is perfectly valid), so you'll have to adjust the value according to the strings you want to be valid.
One could also argue that a text with only 2 or 3 combining characters per letter is not "zalgo enough", even if it's not a valid text in the languages that your application accepts. Anyway, defining an accurate criteria that works for all cases is hard and depends on the context.
---
Another way - if the programming language you're using doesn't support Regex Unicode Properties - is to simply loop through the string and count the combining characters:
```python
# Python
from unicodedata import combining
text = # string I want to check
count = 0
max_allowed = 3 # maximum of 3 consecutive combining characters allowed
for c in text:
if combining(c):
count += 1
if count > max_allowed:
print('Zalgo!')
break
else:
count = 0
else:
print('not zalgo')
```
I used Python as an example, but the ideia is the same in any other language: count the characters, and when the limit of consecutive combining characters is reached, report the text as Zalgo.
---
Both approaches above don't need to check all the string, as they stop at the first "zalgo character" found. The consequence is that they will consider this as Zalgo:
> this text has only one "zalgo char": T̃͟͏̧̟͓̯̘͓͙͔ - the rest is just normal text
Because it considers a text to be Zalgo if it finds a single ocorrence of consecutive combining characters. But it's not hard to adapt the algorithms above to consider only cases when all letters are "_zalgified_" (or at least N letters are, with N varying according to any criteria you want).
---
Anyway, there's no silver bullet. The bigger `max_allowed` is, the less cases of potential Zalgo Texts are not detected.
Another approach to this problem would be: instead of trying to detect Zalgo Text, you could have a whitelist of letters and their respective list of allowed combining characters - and that will vary according to the languages you want to accept.
Example: in Portuguese, vowels can be followed by a [COMBINING ACUTE ACCENT](https://www.fileformat.info/info/unicode/char/301/index.htm), [COMBINING CIRCUMFLEX ACCENT](https://www.fileformat.info/info/unicode/char/302/index.htm) or [COMBINING TILDE](https://www.fileformat.info/info/unicode/char/303/index.htm) (**only one** of them at a time). The letter `c` can be followed by a [COMBINING CEDILLA][3], and letter `a` can also be followed by a [COMBINING GRAVE ACCENT](https://www.fileformat.info/info/unicode/char/300/index.htm). So the regex will be like this:
```php
// PHP, checking valid combining characters in Portuguese
if (preg_match('/c[^\P{M}\x{327}]|[^aeiouc]\p{M}|[eiou][^\P{M}\x{301}-\x{303}]|a[^\P{M}\x{300}-\x{303}]/iu', $texto)) {
echo "invalid\n";
} else {
echo "valid\n";
}
// PS: it's a "simplified" version, because some vowels don't accept all the accents
```
This could be harder to do, if the languages you want to accept have lots of different and complicated rules. But the trade-off is that it'll be more accurate, although it'll also reject any text that's not compliant with the language grammar (not only Zalgo, but also typos and maybe "not-zalgo-enough" texts, whatever that means).
And in the end, you must also define what your real problem is: do you want to detect Zalgo (something that has that "creepy appearance") or to reject any invalid text (given a list of accepted languages)?
Anyway, there's no one-size-fits-all solution. But once you know how a Zalgo Text is created, you can adapt the solution according to your needs.
[1]: https://i.stack.imgur.com/olrFQ.png
[2]: https://i.stack.imgur.com/3e77q.png
[3]: https://www.fileformat.info/info/unicode/char/327/index.htm