Welcome to Software Development on Codidact!
Will you help us build our independent community of developers helping developers? We're small and trying to grow. We welcome questions about all aspects of software development, from design to code to QA and more. Got questions? Got answers? Got code you'd like someone to review? Please join us.
Post History
any DOM "tree" node is actually a "branch" Not exactly. Document Object Model and Nodes According to the MDN documentation, the DOM (Document Object Model) is "the data representation of the...
#1: Initial revision
by
 hkotsubo
·
2022-04-27T17:04:03Z (about 3 years ago)
hkotsubo
·
2022-04-27T17:04:03Z (about 3 years ago)
> *any DOM "tree" node is actually a "branch"*
Not exactly.
# Document Object Model and Nodes
According to the [MDN documentation](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction), the DOM (Document Object Model) is "*the data representation of the objects that comprise the structure and content of a document on the web.*"
It's a hierarchical tree-like structure, in which all parts of the document are organized. And by "_all parts_", I mean: elements, attributes, text, comments, etc. **Each of these individual parts is a node**.
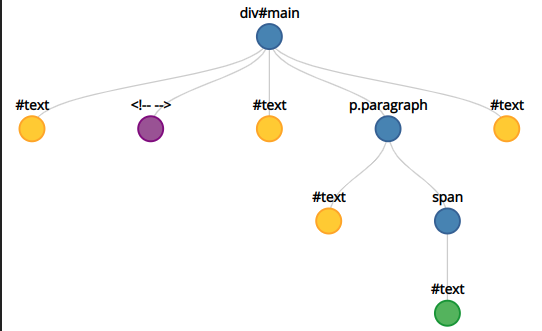
For example, for this simple HTML:
```html
<div id="main">
<!-- some comment -->
<p class="paragraph" style="font-weight: bold">abc<span>def</span></p>
</div>
```
The DOM tree will be like this (**the circles are the nodes**):
Or, if you prefer ASCII diagrams:
```none
div#main
________________________________|_________________________
| | | | |
text <!-- some comment --> text p.paragraph text
(line break) (line break) | (line break)
|
_______________
| |
text ("abc") span
|
text ("def")
```
Each HTML element is a node. But there are also text nodes (such as "abc" inside the paragraph and "def" inside the `span`, and also all the line breaks: one right after the `div` opening tag, another one right after the comment, and another one before the closing `</div>`).
Note that the comment is also a node. And the attributes are nodes as well (the `id` attribute in the `div`, and the `class` and `style` attributes in the paragraph, are all nodes), although those are not shown in the image above, because "*I couldn't find space to fit them*" (but they are nodes too).
---
# `nodeType`
The `nodeType` property just returns a value that tells the type of the node.
In your code, `e.nodeType == Node.TEXT_NODE` is just checking if the node (referenced by variable `e`) is a text node. It's just a way to know the node's type (and do whatever you need based on that type).
A common use case is when you're looping through a collection of nodes and wants to do something only if the node is of a specific type (or perform a different action for each type, etc).
You can find all the existing types in the [documentation](https://developer.mozilla.org/en-US/docs/Web/API/Node/nodeType) and the [DOM Living Standard](https://dom.spec.whatwg.org/#ref-for-dom-node-nodetype%E2%91%A0):
| Node Type | Value | Description |
|----------------------------------|-------|-------------------------------------------------------------------------------|
| Node.ELEMENT_NODE | 1 | An `Element` node like `<p>` or `<div>` |
| Node.ATTRIBUTE_NODE | 2 | An `Attribute` of an `Element` |
| Node.TEXT_NODE | 3 | The actual `Text` inside an `Element` or `Attr` |
| Node.CDATA_SECTION_NODE | 4 | A `CDATASection`, such as `<!CDATA[[ … ]]>` |
| Node.PROCESSING_INSTRUCTION_NODE | 7 | A `ProcessingInstruction` of an XML document, such as `<?xml-stylesheet … ?>` |
| Node.COMMENT_NODE | 8 | A Comment node, such as `<!-- … -->` |
| Node.DOCUMENT_NODE | 9 | A `Document` node |
| Node.DOCUMENT_TYPE_NODE | 10 | A `DocumentType` node, such as `<!DOCTYPE html>` |
| Node.DOCUMENT_FRAGMENT_NODE | 11 | A `DocumentFragment` node |
Note that each type has a numerical value. So `e.nodeType == Node.TEXT_NODE` could also be written as `e.nodeType == 3`, but using `Node.TEXT_NODE` makes the code more clear IMO.