Welcome to Software Development on Codidact!
Will you help us build our independent community of developers helping developers? We're small and trying to grow. We welcome questions about all aspects of software development, from design to code to QA and more. Got questions? Got answers? Got code you'd like someone to review? Please join us.
How this recursive treewalker works?
Credit for User:Meriton for developing the following code (first published here).
function replaceIn(e) {
if (e.nodeType == Node.TEXT_NODE) {
e.nodeValue = e.nodeValue.replaceAll("a", "");
} else {
for (const child of e.childNodes) {
replaceIn(child);
}
}
}
replaceIn(document.body);
How this recursive treewalker works?
As a side question which I grasp as important, can there be an even simpler and more direct version without the else?
3 answers
You are accessing this answer with a direct link, so it's being shown above all other answers regardless of its score. You can return to the normal view.
How this recursive treewalker works?
To understand what the code does, we need to first see what problem it's trying to solve and why it needs to be solved this way.
Let's consider this HTML:
<body>
<a href="www.whatever.com">Whatever <i>site</i></a>
<div><p>abc<span>def</span></p></div>
</body>
It's rendered as:

And it's represented by the following DOM tree:
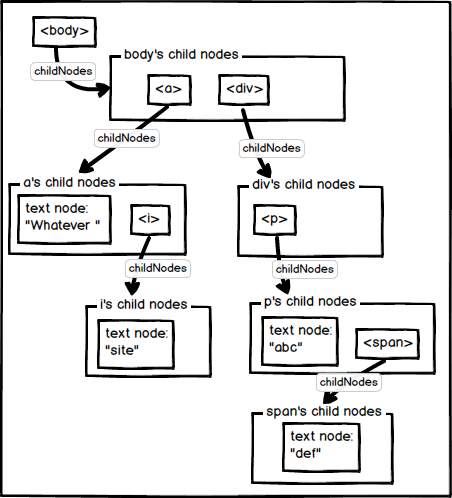
The same diagram in ASCII:
+---------------+
| element: body |
| |
| childNodes |
+--- | ---------+
|
\__ body's first child node
| +------------+
| | element: a |
| | |
| | childNodes |
| +--- | ------+
| |
| a's first child node..........a's second child node
| +------------------------+ +------------+
| | text node: "Whatever " | | element: i |
| | | | |
| | no childNodes | | childNodes |
| +------------------------+ +--- | ------+
| |
| i's first child node
| +-------------------+
| | text node: "site" |
| | |
| | no childNodes |
| +-------------------+
|
\__ body's second child node
+--------------+
| element: div |
| |
| childNodes |
+--- | --------+
|
div's first child node
+------------+
| element: p |
| |
| childNodes |
+--- | ------+
|
p's first child node....p's second child node
+------------------+ +---------------+
| text node: "abc" | | element: span |
| | | |
| no childNodes | | childNodes |
+------------------+ +--- | ---------+
|
span's first child
+------------------+
| text node: "def" |
| |
| no child nodes |
+------------------+
The structure is basically:
-
bodyhas two child nodes: tagsaanddiv-
ahas two child nodes: a text node with the text "Whatever ", and tagi-
ihas one child node: a text node with the text "site"
-
-
divhas one child node: tagp-
phas two child nodes: a text node with the text "abc", and tagspan-
spanhas one child node: a text node with the text "def"
-
-
-
- And the text nodes don't have child nodes.
Actually, all the line breaks are also text nodes (such as the line break after
<body>opening, another one after</a>closing, etc), but I'm omitting those for the sake of simplicity.
The original problem that resulted in this code is to replace some character in all parts of the document where that character appears. To avoid replacing things that shouldn't be replaced (such as HTML tags and attributes, as already explained in answers for the original question), a better solution is to replace only the text nodes.
Note that different parts of the text are spread through the DOM tree. In this case, there are four text nodes, each one in a different part of the hierarchy. To replace all text nodes, you'll need to traverse through the tree and visit all of them, one by one.
But to reach all text nodes, you need to visit all other nodes, because a node is only reachable by its parent: starting at body, you can reach a and div; from a you can reach the text node "Whatever " and tag i, and so on. Therefore, only by traversing the whole structure, you can be sure that all text nodes were visited and replaced. In other words, you need something like this:
- start at the
bodyelement - check its child nodes (
aanddiv):- for each child node you check if they are text nodes and replace them
- then, we must check their children:
a's child nodes anddiv's child nodes -
a's children are the text node "Whatever " and tagi- for each one of those child nodes, check if they are text nodes and replace them
- then check for those child nodes' child nodes (the text node has no children, but
idoes)- and so on...
-
div's children isp- for that child node, check if it's a text node and replace it
- then check for
p's child nodes- and so on...
An initial pseudo-code to do that would be like this:
if (body is text node) {
replace its text
} else {
for each body's child nodes, do:
if (child node is text node) {
replace its text
} else {
for each child node's child nodes, do:
if (child node's child node is a text node) {
replace its text
} else {
for each child node of child node's child nodes, do:
and so on...
}
}
}
A first problem with this approach is: I don't know how many levels the DOM tree has (I know for this specific one, but think of an algorithm that should work for any HTML page), so how can you know how many nested loops to use? We could assume some value ("I'll work with N levels"), but a better solution would work regardless of the number of levels. How could this be made?
We could start with a simple function that handles only the first level (body and its children):
// first version, incomplete
function replaceIn(e) {
// check if the node is a text node
if (e.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
e.nodeValue = e.nodeValue.replaceAll("a", "");
} else {
// for each child node
for (const child of e.childNodes) {
// do something with the child node
}
}
}
Then we could call replaceIn(document.body), and the function will do the following:
- check if
bodyis a text node (if it is, replace it) - but
bodyisn't a text node, so it enters theelseclause, and execute the loop inbody's child nodes
body's child nodes are a and div, so we need another function to check those. This function must check if the child node is a text node. If it is, replace its text. If it's not, loop through its child nodes and check each one of them:
// second version: function to check child nodes
function checkChild(childNode) {
if (childNode.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
childNode.nodeValue = childNode.nodeValue.replaceAll("a", "");
} else {
// check the childNode's child nodes
for (const child of childNode.childNodes) {
// do something with the child node
}
}
}
// now we can use the new function to check the child nodes
function replaceIn(e) {
// check if the node is a text node
if (e.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
e.nodeValue = e.nodeValue.replaceAll("a", "");
} else {
// for each child node
for (const child of e.childNodes) {
checkChild(child); // <---- ** HERE: ** use the new function to check the child node
}
}
}
Now when we call replaceIn(document.body), the function will do the following:
- check if
bodyis a text node (if it is, replace it) - but
bodyisn't a text node, so it enters theelseclause, and execute the loop inbody's child nodes - for each child node (in this case,
aanddiv), calls thecheckChildfunction.- in the first iteration, it'll call
checkChildpassing theaelement as argument- the
checkChildfunction checks ifais a text node - it's not, so it enters the
elseclause and loops througha's child nodes (which are the text node "Whatever " and the tagi)- now we need another function to check those child nodes
- the
- in the second iteration, it'll call
checkChildpassing thedivelement as argument- the
checkChildfunction checks ifdivis a text node - it's not, so it enters the
elseclause and loops throughdiv's child nodes (which is the tagp)- now we need another function to check this child node
- the
- in the first iteration, it'll call
With that, we could reach 2 levels (body's child nodes and body's "grandchild" nodes). But we ended up with the same problem: now we need a function to check the grandchildren. Maybe if we do that:
// third version: function to check granchild nodes
function checkGrandChild(grandChildNode) {
if (grandChildNode.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
grandChildNode.nodeValue = grandChildNode.nodeValue.replaceAll("a", "");
} else {
// check the grandChildNode's child nodes
for (const child of grandChildNode.childNodes) {
// do something with the child node
}
}
}
// now we can use the new function to check the grandchild nodes
function checkChild(childNode) {
if (childNode.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
childNode.nodeValue = childNode.nodeValue.replaceAll("a", "");
} else {
// check the childNode's child nodes (AKA "grandchild" nodes)
for (const child of childNode.childNodes) {
checkGrandChild(child); // <---- ** HERE: ** use the new function to check the grandchild node
}
}
}
function replaceIn(e) {
// check if the node is a text node
if (e.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
e.nodeValue = e.nodeValue.replaceAll("a", "");
} else {
// for each child node
for (const child of e.childNodes) {
checkChild(child);
}
}
}
Now we could handle 3 levels, but still need another function to check the grand-grandchild nodes.
Wait a minute, have you noticed that the checkChild and checkGrandChild functions are doing basically the same as the replaceIn function? All of them receives a node and do the following:
- if the node is a text node, replace its text
- if it's not a text node, loop through its child nodes
- for each child node, call a function that will execute steps 1 and 2 on that node
And if all functions are doing the same thing, why not use only one of them? In this case, we could use the replaceIn function:
function replaceIn(e) {
// check if the node is a text node
if (e.nodeType == Node.TEXT_NODE) {
// it's a text node, then replace its text
e.nodeValue = e.nodeValue.replaceAll("a", "");
} else {
// for each child node
for (const child of e.childNodes) {
replaceIn(child);
}
}
}
And that's it. When you call replaceIn(document.body), it's executed as follows:
-
1: check if
bodyis a text node; it's not, so loops throughbody's child nodes -
2:
body's first child isa-> recursive call-
2.1: check if
ais a text node; it's not, so loops througha's child nodes -
2.2:
a's first child is the text node "Whatever " -> recursive call- 2.2.1: check if it's a text node. It is, so replace its text (it becomes "Whtever")
-
2.3:
a's second child isi-> recursive call-
2.3.1: check if
iis a text node; it's not, so loops throughi's child nodes -
2.3.2:
i's first child is the text node "site" -> recursive call- 2.3.2.1: check if it's a text node. It is, so replace its text (in this case, there's no letter "a" in the text, so it remains unchanged)
-
2.3.1: check if
-
2.1: check if
-
3:
body's second child isdiv-> recursive call-
3.1: check if
divis a text node; it's not, so loops throughdiv's child nodes -
3.2:
div's first child isp-> recursive call-
3.2.1: check if
pis a text node; it's not, so loops throughp's child nodes -
3.2.2:
p's first child is the text node "abc" -> recursive call- 3.2.2.1: check if it's a text node. It is, so replace its text (it becomes "bc")
-
3.2.3:
p's second child isspan-> recursive call-
3.2.3.1: check if
spanis a text node -
3.2.3.2: it's not, so loops through
span's child nodes -
3.2.3.3:
span's first child is the text node "def" -> recursive call- 3.2.3.3.1: check if it's a text node. It is, so replace its text (in this case, there's no letter "a" in the text, so it remains unchanged)
-
3.2.3.1: check if
-
3.2.1: check if
-
3.1: check if
In step 1, we're at "level 1" (checking document.body).
Step 2 is when the first recursive call is made: we're inside the for, looping through body's child nodes, and call replaceIn(child). At the first loop iteration, child will be a, so replaceIn will receive this element as argument.
At step 2.2, we're at the for loop, but now it's looping through a's child nodes, and we make another recursive call: replaceIn now receives the text node "Whatever", check that it's a text node, and replace it. Then we can proceed to a's next child, which is i (then another recursive call is made at step 2.3, and so on).
The same happens for all other nodes in the hiearchy. For each one, check its type. If it's a text node, replace; otherwise loop through its child nodes and repeat the same steps for each child (and the recursive call is the way to "repeat the same steps").
Each recursive call is made to "go into a new level" in the hierarchy (first to check body's children, then to check its grandchildren, then the grand-grandchildren and so on). I've put numbers to indicate those (every new level adds a new number, such as the call in step 2 goes to 2.1).
With this, you don't need to know how many levels the DOM tree has. For each new level, it'll make another recursive call, until there are no more levels to check. In the end, all nodes will be visited, and all the text nodes are replaced.
Important note: actually, the function receives a node where the replacement will start. In the examples above, I'm calling the function as replaceIn(document.body), so the algorithm starts at the body element and replace everything below it. But if I call replaceIn(someOtherElement), the replacement will be made only in that specific element (and all the tags inside it), instead of the whole page.
can there be an even simpler and more direct version without the
else?
For this particular case, yes, you can remove the else clause:
function replaceIn(e) {
if (e.nodeType == Node.TEXT_NODE) {
e.nodeValue = e.nodeValue.replaceAll("a", "");
}
for (const child of e.childNodes) {
replaceIn(child);
}
}
That's because text nodes don't have child nodes, so their childNodes property will always be empty (hence, for those nodes, there will be no elements to be traversed in the for..of loop, and the final result will be the same).
But there's an important aspect to consider.
if/else statements exist for a reason. When I do:
if (condition) {
A
} else {
B
}
I'm saying that if the condition is true, do A, otherwise, do B. It's a choice between one or another, based on the condition.
But if I do:
if (condition) {
A
}
B
Then B is always done, regardless of the condition being true or false. Removing the else statement is not a matter of being simpler or more direct, it can completely change the algorithm.
As I said, for this particular case, both ends up being equivalent, just because text nodes don't have child nodes.
Nevertheless, I still prefer to keep the else clause, because it conveys intention and semantics: if it's a text node, do this, if it's not, do that. It makes clear that the loop must not be made on text nodes.
1 comment thread
To understand the concept of recursive tree traversal, I would like to give you an analogy. Imagine a labyrinth of rooms connected like a tree structure. That is, there is an entry to the first room, and when entering a room you may find doors leading into rooms deeper down into the labyrinth, but it is guaranteed that there are no cycles.
Some rooms only have an entry, but don't lead to further rooms (leaves of the tree). Of these, some have walls that are painted blue and some of these have walls that are painted green.
Your task is to go through all rooms and paint the blue ones and only the blue ones yellow. With you, you take a rope that will always show you the way back to the entrance of the labyrinth. Or, in other words, when you are in one room, the rope will show you how to get back to the room from where you entered the current room. In addition to the rope you have some pen and lots of fresh sticky note sheets with you.
Your algorithm would start by entering the labyrinth, that is, go into the first room. From then on, you will do the following:
After entering a room:
take a fresh sheet from your sticky notes and stick it to a wall
if the room has blue walls:
paint the blue walls yellow
otherwise:
for each door (from left to right), if any, leading to a new room:
write to the sticky note which is the next door to enter
enter that door and follow these instructions again.
as you are now done with this room, dispose of the sticky note
use the rope to return to the room from where you came
This algorithm is just a translation of your tree-traversal: A node in the tree that is a TEXT_NODE is known to be a leaf of the tree and it contains text to be replaced. This corresponds to the rooms with the blue walls: We know that there are no further rooms from such a room, but we know we have to do the painting here.
Any other node may or may not have child nodes (there are other leaf nodes than TEXT_NODEs, but their list of children is just empty). That is, if there are child nodes, for each child node move there and do just the same thing again. Now, look at the labyrinth analogy: The non-bluish rooms may be the green ones (from which no doors lead further), or just other rooms from which you can move into further rooms deeper down the labyrinth.
Finally, the sticky notes and the rope: These two represent the computer stack. Each sticky note is for data (variables) in the current room (the current depth of recursion): You get a fresh sticky note on entering the room, as you get a new set of local variables with each recursive call. The rope always brings you back to the room from which you entered the current room. Following the rope back corresponds to returning from the innermost recursive function call.
Note: This answer was written for a version of the question that focused on getting rid of the if-else, rather than on an explanation of the workings of the recursive tree-traversal.
One way of getting rid of if-elses to achieve uniform handling of different objects is to hide the distinction in lower levels of abstraction:
Imagine a bowl of apples and bananas. Basically, you just want to eat all of them. However, if you one by one pick the bowl contents, you first have to check if you have a banana - which you need to peel before you bite into it. That is, your algorithm is "for each fruit: if banana, peel then eat, if apple, eat". You can abstract it by introducing a function "prepare_for_eating". Then your algorithm is "for each fruit: prepare_for_eating(fruit) then eat(fruit)". Seems as if the if-else has disappeared. But, if you look inside the "prepare_for_eating" function, you will again have the original if-else statement where you decide to peel or not to peel.
With object oriented techniques you can hide if-elses behind method calls: A Fruit base class would provide a member function "prepare_for_eating". For banana, this would contain the "peel" statement, for the apple, this would be empty. The algorithm would be "for each fruit: fruit.prepare_for_eating then fruit.eat". If fruit happens to be a banana, the banana member function doing the peel would be called. For an apple object, the apple member function would be called that does nothing.
You can use other tricks to get rid of if-elses by computing boolean expressions and use their result as zero or one in multiplications or table lookups. For example:
if x == 42 then x = -1
can be re-written as (assuming true can be used as 1 and false as 0):
x = (x == 42) * -1 + (x != 42) * x;
Or, using such a result for table lookups:
action_table = [peel, do_nothing]
for each fruit: call action_table[fruit is apple] then eat;
Whether any of the above ideas can be applied meaningfully to your problem and is suited to fulfill your expectations is up to you.

2 comment threads